The LLM Gateway: The Missing Brick in Your AI Platform Architecture


Why every CIO, CTO, and CISO should treat the LLM Gateway as critical infrastructure — not an afterthought.
You've greenlit AI projects. Your teams are experimenting with large language models. Developers are integrating APIs from OpenAI, Anthropic, Mistral, and open-source alternatives hosted on your own infrastructure. The momentum is real.
But here's the uncomfortable truth: without a centralized LLM Gateway sitting between your organization and every model it consumes, you are building on sand. You have no unified control plane. No cost visibility. No audit trail. No kill switch.
This article lays out why the LLM Gateway is the single most consequential architectural decision you will make in your AI platform strategy — and why sovereign, open-source options should be at the top of your evaluation list.
What Is an LLM Gateway, Exactly?
An LLM Gateway is a reverse proxy and control layer that sits between your applications (or your users) and the large language models they interact with — whether those models run on third-party cloud APIs, on a private cloud, or on-premise on your own GPU clusters.
Think of it as the API Gateway pattern, battle-tested in microservices for a decade, applied specifically to the unique challenges of generative AI consumption.
Every prompt goes through it. Every response comes back through it. Nothing bypasses it. That single chokepoint is the entire point — and the entire value.
The Seven Pillars of an LLM Gateway
1. FinOps: From AI Cost Black Box to Transparent Budget Control
Generative AI costs are notoriously opaque. Token-based pricing varies across providers and models. A single poorly designed agent loop can burn through thousands of dollars in minutes. Without centralized metering, your finance team is flying blind until the invoice arrives.
An LLM Gateway gives you real-time cost observability per team, per project, per application, and per model. It lets you set hard budget ceilings, enforce quotas, and trigger alerts before overruns happen — not after. The FinOps capability alone typically justifies the deployment.
Key FinOps functions a gateway enables:
- Token-level metering and cost attribution by business unit, project, or environment (dev, staging, production).
- Budget caps with automatic request throttling or blocking when thresholds are reached.
- Comparative cost analysis across models and providers, enabling data-driven procurement decisions.
- Chargeback and showback reporting for internal consumers of AI services.
Without this, your AI expenditure is an unmonitored credit card handed to every team with API access.
2. Security: A Single Enforcement Point for Every Model Interaction
Your security perimeter must extend to LLM interactions. Full stop. Every prompt sent to a model is a potential data exfiltration vector. Every response returned is a potential injection surface.
An LLM Gateway is where you enforce:
- Prompt sanitization and injection defense. Detect and block prompt injection attacks, jailbreak attempts, and adversarial inputs before they reach the model.
- Data loss prevention (DLP). Scan outgoing prompts for sensitive data — PII, credentials, proprietary source code, trade secrets — and redact or block them. This is especially critical when prompts are routed to third-party cloud APIs.
- Response filtering. Inspect model outputs for hallucinated sensitive data, harmful content, or policy violations before they reach end users.
- mTLS, authentication, and authorization. Ensure that only authenticated, authorized services and users can invoke model endpoints, with full identity context attached to every request.
If your developers are calling LLM APIs directly from application code with hardcoded API keys, you have already lost control. The gateway is how you take it back.
3. Governance and Compliance: The Audit Layer Regulators Will Ask For
The EU AI Act is here. Industry-specific regulations around AI transparency and accountability are accelerating globally. Your board, your regulators, and your clients will ask you the same question: can you demonstrate that your AI usage is governed, traceable, and compliant?
An LLM Gateway provides the governance backbone:
- Policy-as-code enforcement. Define which models are approved for which use cases. Block unapproved models. Restrict certain data classifications from being sent to specific providers or geographies.
- Immutable audit trails. Every prompt and response, timestamped, attributed to a user or service, and stored in tamper-evident logs. This is not optional — it is the evidentiary foundation of your AI compliance posture.
- Consent and usage-policy gating. Enforce terms of use, acceptable use policies, and data processing agreements at the gateway level.
- Sovereignty enforcement. Route requests to ensure that data residency requirements are met — e.g., ensuring European user data is processed only by models hosted within EU jurisdictions.
4. Model Portability: Eliminating Vendor Lock-In by Design
One of the most strategically dangerous mistakes in enterprise AI is coupling your applications tightly to a single model provider's API. Models evolve. Pricing changes. New capabilities emerge from competitors. Open-source models close the gap at remarkable speed.
The LLM Gateway abstracts the model layer. Your applications call the gateway using a standardized interface. The gateway routes to the appropriate model based on policies you define — cost, performance, data sensitivity, latency requirements, or availability.
This gives you:
- Zero-downtime model switching. Migrate from one provider to another, or from a cloud-hosted model to a self-hosted open-source model, without changing a single line of application code.
- A/B testing and canary deployments for models. Route a percentage of traffic to a new model and compare output quality, latency, and cost before full cutover.
- Fallback and resilience. If one provider experiences an outage or degradation, automatically failover to an alternative model.
- Negotiation leverage. When your vendor knows you can switch providers with a configuration change, your procurement conversations change dramatically.
5. Quotas, Rate Limiting, and Fair Usage
In any organization with more than a handful of AI consumers, resource contention is inevitable. One team's batch processing job should not starve another team's customer-facing application of capacity.
The gateway enforces:
- Per-team, per-application, and per-user rate limits and quotas.
- Priority queuing — ensuring latency-sensitive production workloads take precedence over exploratory or batch workloads.
- Graceful degradation strategies — falling back to smaller, faster models under load rather than dropping requests entirely.
This is capacity management for AI, and it is as essential as it is for any other shared infrastructure service.
6. Comprehensive Logging: The Foundation of AI Observability
If you cannot see what your AI systems are doing, you cannot secure them, optimize them, or trust them. The LLM Gateway is the natural point to capture a complete, structured log of every interaction.
This is not just about compliance. The operational and strategic value of comprehensive logging is enormous:
- Cybersecurity analysis. Detect anomalous usage patterns — bulk data extraction attempts, adversarial probing, privilege escalation via prompt manipulation. Feed interaction logs into your SIEM for correlation with other security telemetry.
- Usage verification and AI ethics monitoring. Ensure that AI is being used in accordance with your organization's acceptable use policies. Identify misuse, policy drift, or shadow AI usage before it becomes a liability.
- Quality and performance monitoring. Track response latency, error rates, hallucination patterns, and output quality over time. Build feedback loops that inform model selection, prompt engineering improvements, and fine-tuning decisions.
- Training data curation. With proper consent frameworks, logged interactions become a goldmine for building proprietary evaluation datasets and for fine-tuning domain-specific models — creating a compounding competitive advantage.
The key architectural decision here is where and how you store these logs. They will contain sensitive data. They must be encrypted at rest and in transit, access-controlled, and subject to retention policies aligned with your data governance framework.
7. Caching and Performance Optimization
An often overlooked but high-impact capability: semantic caching. Many organizations discover that a significant percentage of LLM queries are repetitive or semantically similar. A gateway with semantic caching can return cached responses for near-identical prompts, dramatically reducing latency and cost — sometimes by 30 to 60 percent for common workloads.
Additional performance capabilities include:
- Response streaming management.
- Request batching and queue optimization.
- Automatic prompt compression for cost reduction without meaningful quality loss.
The Sovereignty and Open-Source Imperative
Here is where the architectural decision becomes a strategic one.
If your LLM Gateway is a proprietary SaaS product operated by a cloud hyperscaler or a VC-funded startup, you have introduced a new single point of dependency — and potentially a new data exfiltration surface — into the most sensitive layer of your AI stack. Every prompt and every response flows through infrastructure you do not control, operated by an entity whose incentives may not permanently align with yours.
This is why open-source LLM Gateways deserve serious consideration as the default choice.
Several mature, production-grade open-source projects exist in this space. Solutions built on open-source foundations give you:
- Full auditability of the control plane. You can inspect every line of code that processes your prompts and responses. No black boxes. No trust-us assurances. This is especially critical for regulated industries and defense-adjacent organizations.
- Deployment flexibility. Run the gateway on-premise, in your own cloud tenancy, in an air-gapped environment, or in a hybrid configuration. You choose the deployment topology that matches your threat model — not the vendor's cloud region map.
- No telemetry exfiltration. Open-source gateways do not phone home. Your usage patterns, prompt volumes, and model preferences are not training data for someone else's product roadmap.
- Community-driven security. Vulnerabilities are discovered and patched in the open, by a global community, under public scrutiny. This is a fundamentally stronger security model than hoping a vendor's internal team catches everything.
- Long-term continuity. Open-source projects cannot be acquired, sunset, or repriced overnight. You always have the code. You always have the option to fork and maintain it independently.
Projects to evaluate in this space include LiteLLM (a widely adopted open-source LLM proxy that provides a unified OpenAI-compatible interface across 100+ model providers), MLflow AI Gateway (part of the mature MLflow ecosystem), Kong and Apache APISIX (established API gateways with growing LLM-specific plugin ecosystems), and Envoy-based architectures with custom LLM filters. For organizations seeking a more complete AI platform layer, LangFuse provides open-source observability and analytics that pair naturally with a gateway.
The right choice depends on your maturity, scale, and existing infrastructure. But the guiding principle should be clear: the layer that sees all your AI traffic should be infrastructure you own, operate, and can fully inspect.
Architectural Positioning: Where the Gateway Sits
The LLM Gateway is not a sidecar. It is not an optional middleware. It is a Tier-1 infrastructure component, positioned as follows:
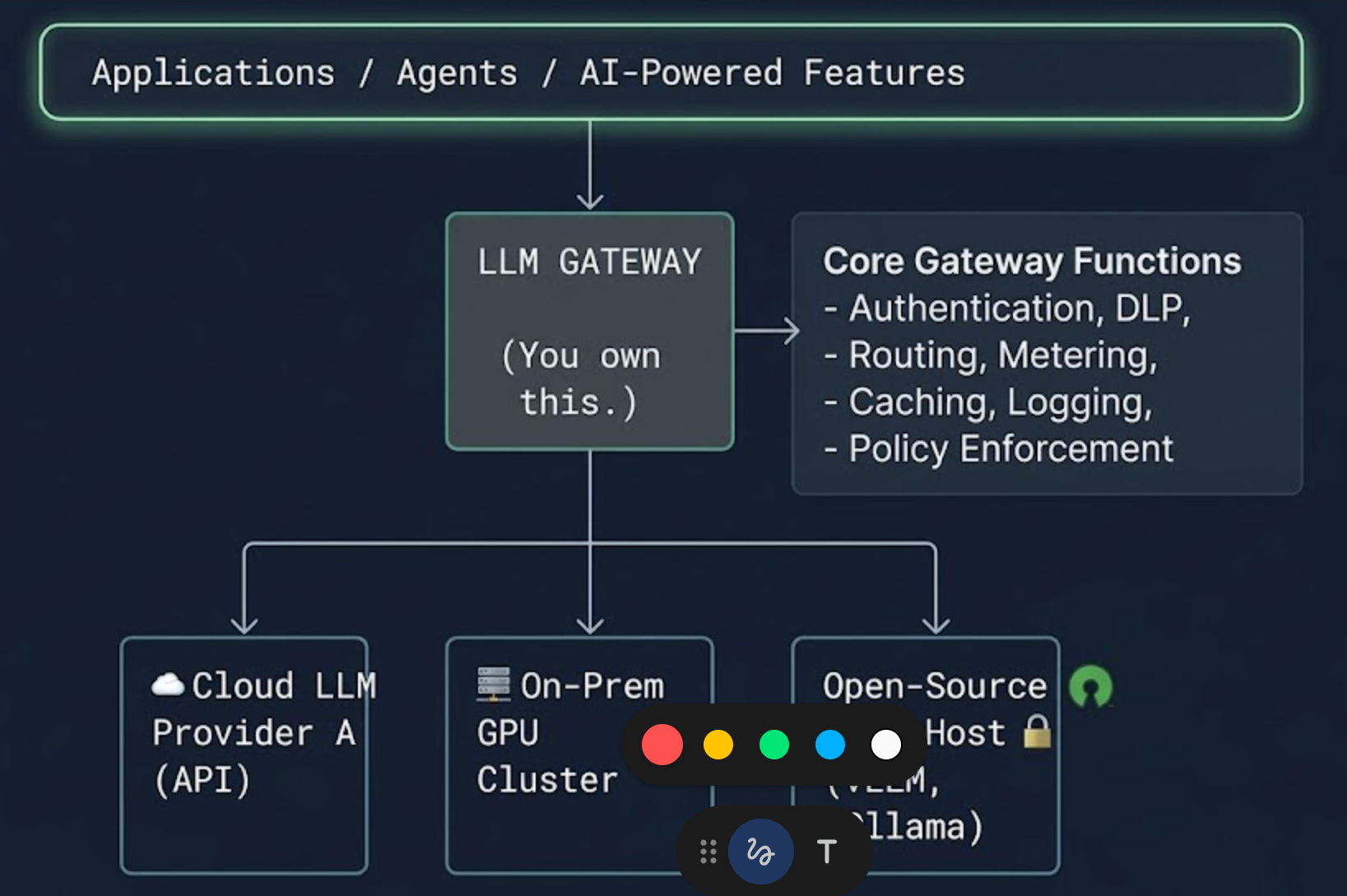
Whether your models are cloud-hosted, on-premise, or a hybrid of both, the gateway is the single plane of glass. It sits in the request path — not alongside it. This is non-negotiable for the control model to work.
For organizations running self-hosted open-source models (via vLLM, TGI, Ollama, or similar inference servers), the gateway is equally critical. Just because the model is inside your perimeter does not mean you can skip metering, access control, logging, or governance. Internal abuse and misconfiguration are threat vectors too.
The Cost of Waiting
Every week that your organization operates AI workloads without a centralized LLM Gateway is a week of:
- Untracked spend that will surprise your CFO.
- Ungoverned data flows that will concern your DPO and your regulators.
- Unlogged interactions that your CISO cannot analyze, and your incident response team cannot investigate.
- Hardcoded provider dependencies that your architects will regret when the market shifts.
- Shadow AI proliferation that undermines every policy you publish.
The LLM Gateway is not a nice-to-have for Phase 3 of your AI roadmap. It is the foundational layer that makes everything else — FinOps, security, compliance, observability, and model agility — possible.
If you are building an AI platform without one, you are not building a platform. You are building technical debt.
Recommendations for Getting Started
- Audit your current state. Map every LLM API call your organization makes today. You will likely discover more direct integrations, more providers, and more spend than anyone expected.
- Evaluate open-source gateways first. Start with LiteLLM or a comparable open-source solution. Deploy it in a non-production environment and route a subset of traffic through it. The time-to-value is measured in days, not months.
- Define your policy framework. Before you enforce anything, document what you want to enforce: approved models, data classification rules, budget limits, acceptable use policies, retention requirements.
- Integrate with your existing security stack. Feed gateway logs into your SIEM. Connect DLP scanning to your existing data classification tools. Make the gateway a first-class citizen in your security architecture, not an island.
- Start logging immediately. Even before you enforce policies, start capturing interaction logs. The historical data will be invaluable for baselining normal usage, detecting anomalies, and informing your governance framework.
- Establish a cross-functional AI platform team. The LLM Gateway sits at the intersection of infrastructure, security, data governance, and FinOps. It cannot be owned by a single team. Establish clear ownership with representation from engineering, security, finance, and compliance.
The organizations that will lead in AI are not those that chase the most models. They are the ones that build the control plane. The LLM Gateway is that control plane.
This is core to what we do at Polynom. We design, deploy, and operate AI platform infrastructure for European enterprises — gateway included — with sovereignty, governance, and measurable P&L impact as non-negotiable foundations. If this is the conversation your leadership team needs to have, we should talk.



