Entreprises, gare à vos données quand vous utilisez les services GPT
Le Monde sortait hier matin un article décrivant l’adoption rapide de l’IA générative dans les entreprises. En effet, soucieux d’optimiser…


Le Monde sortait hier matin un article décrivant l’adoption rapide de l’IA générative dans les entreprises. En effet, soucieux d’optimiser certaines tâches rébarbatives du quotidien, nous sommes déjà nombreux à avoir commencé, parfois sans autorisation explicite de notre hiérarchie, à utiliser ces services.
Mais combien sommes-nous à avoir pris la peine de consulter les conditions de traitements des données ?
Il n’est pas difficile d’imaginer que ceux parmi nous qui utilisent directement les services d’OpenAI à destination des particuliers intègrent de facto la gigantesque communauté de cobayes d’une géante étude de recherche visant a améliorer ces mêmes services. Un rapide coup d’oeil sur la politique de privacy d’OpenAI nous le confirme: ils sont à peu près disposés à partager toutes nos informations personnelles et interactions avec à peu près n’importe qui.
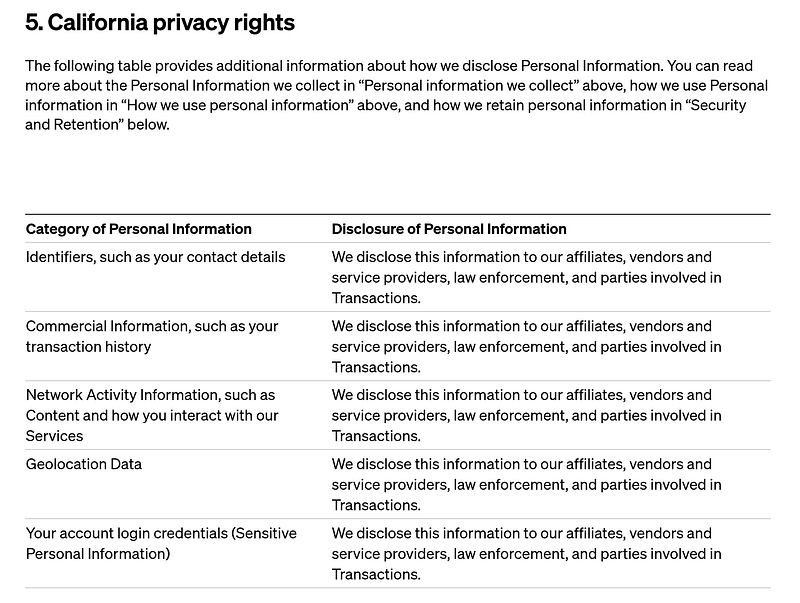
Il est en revanche beaucoup plus déroutant de constater que des services cloud dédiés aux entreprises (et dont le marketing met en avant le caractère hyper sécurisé et les multiples cryptage) ne sont pas tellement meilleurs élèves en la matière.
On citera notamment l’exemple Azure OpenAI Services, qui ouvre (de façon exclusive grâce au partenariat qui lie Microsoft et OpenAI) de nombreux services d’OpenAI à nos grandes entreprises via le cloud Azure.
Une étude plus attentive des conditions de privacy d’Azure OpenAI Services révèlent un curieux dispositif de rétention de données sur une période de 30 jours, couplé à un droit que se réserve Microsoft d’inspecter ces données au cas où on y trouverait des contenus illicites ou à des fins de debugging.
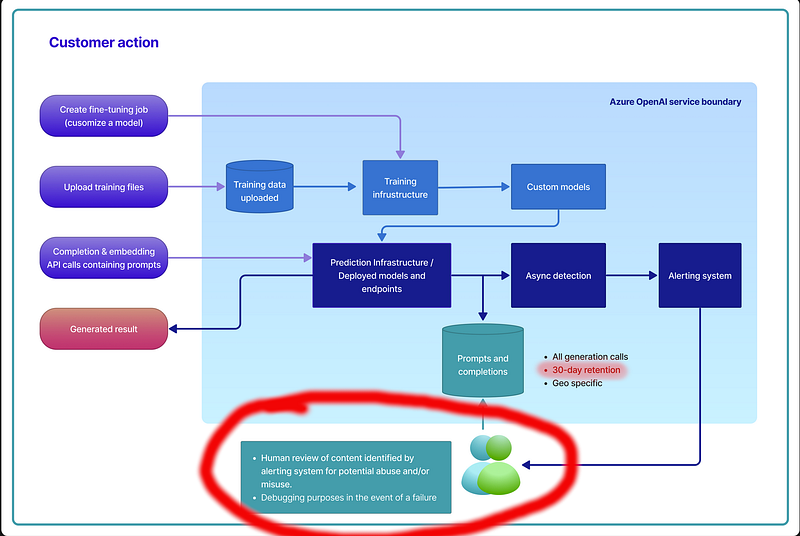
Cette politique de rétention de données échappe à la logique de CMK (clés de cryptage gérées par le client), ce qui rend donc la data complètement exposée.
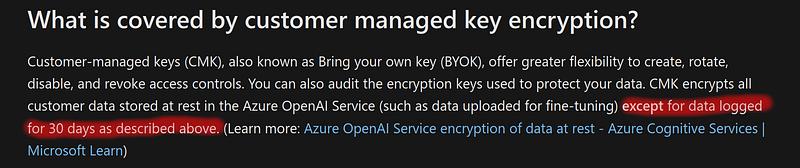
Il est donc à peu près clair que les entreprises sont traitées quasiment à la même enseigne que les particuliers ! Notons au passage que les modèles GPT3 et GPT4 sont entraînés sur des données plus ou moins publiques, et que son IA est restée jusqu’ici relativement ignorante des choses corporate. L’arrivée massive de données venues des entreprises (collectées à des fins de debugging) serait donc une aubaine pour OpenAI qui ne manquerait pas d’en faire profiter ses modèles.
Pourtant, Microsoft prend la peine de préciser que les données ne seront pas utilisées à des fin d’entraînement de l’IA.

Mais alors, pourquoi cette rétention de 30 jours à des fins de debugging, si ce n’est pas pour en faire profiter les modèles d’une manière ou d’une autre? On peut supposer que les données des clients ne seront pas utilisées directement, mais serviront à flagger de nombreuses incohérences et bug qui, in fine, contribueront à l’amélioration des modèles.
Il est donc fort probable que nos grandes entreprises européennes (qui utilisent à peu près toutes la suite Microsoft) travaillent activement à accroître le leadership du tandem OpenAI / Microsoft et renforcent d’autant la souveraineté des américains en la matière, en les nourrissant de leurs données tout en payant fort cher leurs services.
En ce sens OpenAI porte bien son qualificatif “Open” puisqu’il ouvre son IA à toutes les données possibles et imaginables pour mieux enfermer la connaissance du monde dans cette boîte de pandore. Au nez et à la barbe des européens, comme toujours.




