AI Code Review for CIOs: ROI, Governance, and Organizational Scale
A non-blocking, AI-assisted code review model that reduces delivery friction, standardizes quality, and reclaims senior engineering capacity at scale.


Code reviews are essential for quality and security—but at scale they become a structural constraint. Senior engineers turn into bottlenecks, merge requests wait for hours or days, and review quality varies with reviewer availability, fatigue, and expertise.
The business impact is measurable: slower delivery cycles, more context switching, more defects escaping into production, and senior engineers spending a meaningful share of their week on repetitive review work instead of architecture, risk reduction, and engineering enablement.
This article is written for CIOs and technology executives who need to evaluate AI-assisted code review as an operating model lever—not merely a developer tool. If you want implementation details (GitLab/GitHub, scripts, prompts, rate limits), the complete demo is open-sourced in this repository: 📥 synthetic-horizons/ai-code-reviewer.
1) Executive summary: what changes when review becomes instant
AI-assisted code review changes the economics and control points of software delivery.
- Latency collapses: time to first feedback becomes seconds, not hours.
- Senior capacity is reclaimed: routine review work shrinks and shifts upstream.
- Quality expectations standardize: every PR/MR gets the same baseline checks.
- Time to market improves: fewer stalled merges and fewer rework cycles shorten delivery lead time.
- Risk is contained: a non-blocking pattern preserves release flow even when the AI is unavailable.
The result is a system-level effect: the organization becomes less dependent on scarce reviewers and more capable of scaling engineering throughput without proportional overhead.
2) ROI model: consolidating senior capacity, quality, and time-to-market impact
For CIOs, the return on investment of AI-assisted code review should be evaluated as a single, integrated economic model, not as isolated productivity gains. Senior time, quality, and time to market are tightly coupled variables in the software delivery system.
AI review primarily acts on one lever: feedback latency. Reducing latency reshapes how engineering time is spent, how defects propagate, and how quickly value reaches production. The ROI therefore emerges from three reinforcing effects that compound over time.
2.1 The feedback-latency tax: why review queues dominate costs
The most expensive part of code review is rarely the act of reviewing. It is the waiting created by review queues.
When a PR/MR waits hours or days for feedback, developers context switch, parallel work fragments, and fixes are applied with stale mental context. This increases rework, encourages larger batches, and extends cycle time. At scale, review queues transform senior engineers into throughput bottlenecks rather than force multipliers.
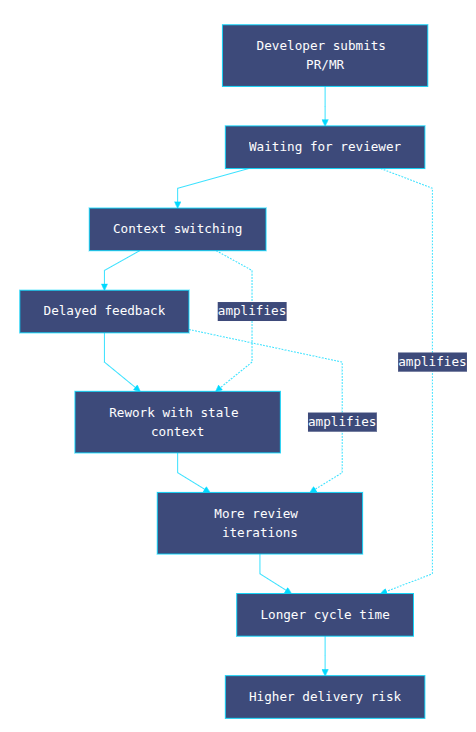
Diagram — Where time is lost in a traditional review loop (feedback-latency tax)
2.2 Reclaiming senior engineering capacity
In a developed-country context, a senior engineer typically represents a total annual employer cost of €90,000–€120,000. Traditional review practices can consume 10–20% of senior time, much of it spent on repetitive baseline checks and rework caused by late feedback.
AI-assisted code review does not replace human judgment. It removes the baseline review layer and shortens rework loops. In practice, organizations frequently reclaim the equivalent of ~€10,000 per year per senior engineer in productive capacity. This time is redirected toward architecture, mentoring, platform enablement, and risk reduction—activities with significantly higher leverage.
2.3 Quality uplift as a cost-avoidance mechanism
Faster and more consistent feedback reduces the likelihood that small issues evolve into costly incidents.
- Defects are identified when code is still fresh in the author’s context.
- Baseline quality checks become systematic rather than reviewer-dependent.
- Human reviewers can focus on high-risk and high-impact changes.
The economic effect is not only fewer defects, but earlier defect correction, which is materially cheaper than post-merge remediation or production incidents.
2.4 Time-to-market acceleration: where executives feel the impact
Time to market is governed by cycle time and its variance. Review latency is a queue, and queues dominate cycle time.
By collapsing time to first feedback from hours or days to seconds, AI review removes the longest idle phase in many PR/MR lifecycles. This produces a compounding effect:
- fewer stalled work items,
- fewer review iterations,
- less coordination overhead,
- more predictable delivery schedules.
From an executive perspective, this translates into the ability to ship faster and more reliably with the same headcount, without introducing new blocking gates.
2.5 A practical ROI framework CIOs can reuse
Perfect precision is unnecessary. Directional clarity is sufficient.
Key inputs
- A = PRs/MRs per month
- B = average wait time to first review (hours)
- C = average senior review effort per PR/MR (minutes)
- D = number of senior engineers regularly reviewing
- E = fully loaded senior cost per hour
- F = average PR/MR cycle time (days)
ROI components to estimate
- senior capacity reclaimed (time shifted to high-leverage work),
- avoided downstream remediation (quality-related cost avoidance),
- cycle-time reduction and variance reduction (time to market).
In most environments, even modest reductions in feedback latency produce returns that vastly exceed the marginal cost of LLM usage.
3) Organizational impact: re-architecting engineering work without a reorg
The value of AI review materializes when organizations treat quality as a continuous responsibility rather than a late-stage checkpoint. This is not a productivity hack; it is a change in how feedback, responsibility, and attention are distributed.
Moving quality upstream
AI review moves baseline quality control to the moment of code submission.
- Issues are addressed when the author’s context is fresh.
- Fixes are cheaper because they happen before downstream dependencies form.
- Human review shifts toward higher-value validation rather than first-line gatekeeping.
The practical effect is fewer review iterations and a tighter, more stable delivery rhythm.
Redefining roles without adding process
Done correctly, AI review changes work allocation without creating new meetings, approvals, or handoffs.
- Developers receive fast, objective feedback and adapt behavior naturally.
- Junior engineers learn continuously through consistent, actionable guidance.
- Senior engineers spend less time on repetitive checks and more on architecture, risk, and system-level decisions.
This redistribution is the core lever: it converts senior attention into organizational capability.
From reviewer dependency to standardized expectations
In many organizations, review quality depends on which reviewer happens to be available. AI introduces a consistent baseline applied across teams, repositories, and time zones.
For leadership, this creates a more governable system:
- less variability in review outcomes,
- reduced review fatigue,
- explicit expectations that scale beyond individual expertise.
Scaling without linear cost
Traditional review models scale poorly because review capacity is constrained by senior availability. As teams grow, queues form, feedback slows, and delivery performance degrades through a compounding latency tax.

AI-assisted review removes this constraint. Baseline checks run instantly and non-blockingly, giving developers immediate feedback while senior engineers focus on architecture and risk—so throughput scales with activity, not headcount.

4) Governance and risk: what CIOs must control
AI review is a software supply chain decision. Governance must be explicit.
Data exposure boundaries
A robust pattern limits what is shared with the model provider.
- Sent: diff content (code changes), repository/project identifiers, detected languages, review guidelines.
- Not sent: full repository history, internal secrets, broader CI environment context.
The goal is to reduce the blast radius while preserving review usefulness.
Vendor, residency, and contract posture
For regulated environments, align the deployment model with policy:
- use providers and configurations that meet residency and contractual requirements,
- or deploy a self-hosted gateway where necessary.
Treat the model provider’s DPA and data handling terms as part of your supplier governance.
Control design principles
A CIO-grade governance posture typically includes:
- minimum token scopes for CI identities,
- secret management through platform-native vaulting,
- repository-level enablement/disablement policies (e.g., exclude repos with sensitive data),
- auditability and monitoring of usage patterns.
The operational objective is to ensure the system is safe by default, and that exceptions are visible and deliberate.
5) Pilot and prove value in 30 days
A successful rollout is not an all-at-once tool deployment; it is an evidence-driven adoption program.
Week 1: proof of value
- Enable on 1–2 non-critical repositories.
- Collect qualitative feedback from developers.
- Measure time to first feedback and review iteration count.
Success criteria: a majority of developers find it helpful and the system does not disrupt delivery flow.
Weeks 2–4: expand with controls
- Roll out to 10–20% of teams.
- Tune guidelines for false positives and stack-specific conventions.
- Establish a cost cap and monitor usage patterns.
Success criteria: acceptable false positive rate, stable costs, and measurable reduction in review latency.
Month 2+: scale as a standard capability
- Default-enable for most repositories.
- Integrate with existing quality gates (SAST, linters, type checkers).
- Formalize governance and ownership (platform team + security).
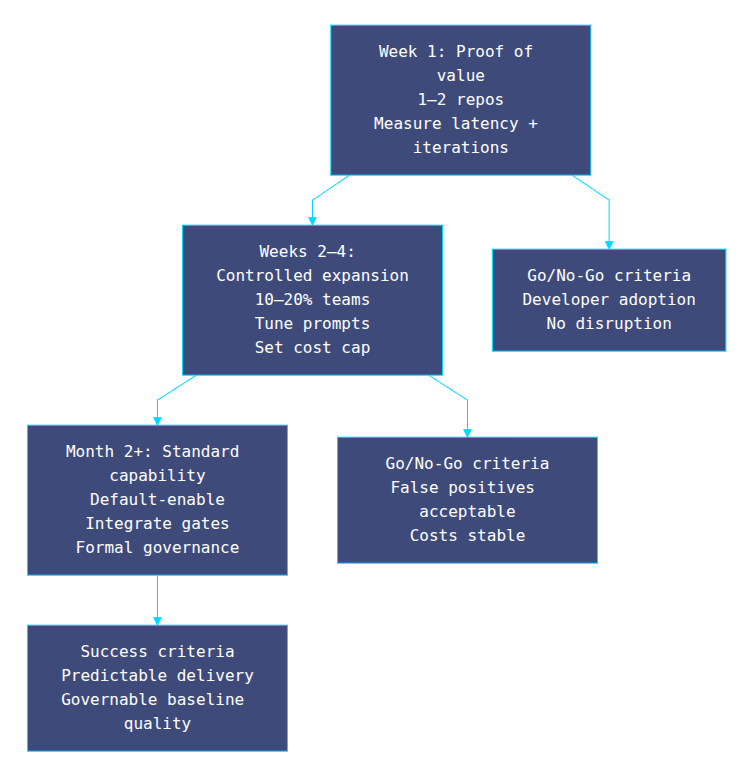
30-day pilot-to-scale adoption path (executive view)
6) Build vs. Buy: When an In-house Script Is Enough and When It Isn’t
An In-house Script implementation like the one provided in the 📥 Github Repo is ideal for experimentation, proof-of-value, and small teams.
However, certain conditions usually trigger a shift to a production-ready solution:
- compliance modes and audit trails,
- observability (metrics, cost tracking, dashboards),
- intelligent batching for large diffs,
- configuration and policy management without code changes,
- organizational rollouts with support and SLAs.
If your operating environment demands these capabilities, treat AI review as a platform component rather than a developer script.
7) What to measure: the KPI dashboard that matters
To manage AI review as an executive capability, track outcomes rather than activity.
Delivery metrics
- time to first feedback
- PR/MR cycle time (lead time to merge)
- number of review iterations per PR/MR
Quality and risk proxies
- defects found pre-merge vs post-merge
- high-severity findings and recurrence
- review coverage (% of PRs/MRs receiving baseline checks)
Economic metrics
- senior time allocation (review vs architecture/enablement)
- marginal cost per PR/MR
- adoption and satisfaction by team
A simple dashboard that reliably trends these metrics is more valuable than a complex one that is rarely used.
8) Next steps
If you want to validate AI-assisted code review quickly, start with a non-blocking pilot and measure the reduction in feedback latency and review iterations.
- Open-source demo implementation: synthetic-horizons/ai-code-reviewer
If you need an enterprise-grade deployment with compliance controls, observability, and hardening, Polynom provides a production-ready solution and implementation support.
Polynom builds high-impact Data & AI products and helps organizations move from proof-of-concept to production-grade systems.
For furhter discussions, contact francois@synthetic-horizons.com or visit polynom.io
This article reflects patterns observed across multiple large-scale engineering organizations.
François Bossière, Ph.D, is co-CEO of Polynom, an AI consulting firm specializing in production-grade Data & AI systems.
Tags: #AI #CodeReview #CIO #SoftwareDelivery #DevOps #Governance #ROI



